Vue.js And SEO: How To Optimize Reactive Websites For Search Engines And Bots

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
 Try ProtoPie AI free →
Try ProtoPie AI free →



 Register Free Now
Register Free Now SurveyJS: White-Label Survey Solution for Your JS App
SurveyJS: White-Label Survey Solution for Your JS AppReactive JavaScript Frameworks (such as React, Vue.js, and Angular) are all the rage lately, and it’s no wonder that they are being used in more and more websites and applications due to their flexibility, modularity, and ease of automated testing.
These frameworks allow one to achieve new, previously-unthinkable things on a website or app, but how do they perform in terms of SEO? Do the pages that have been created with these frameworks get indexed by Google? Since with these frameworks all — or most — of the page rendering gets done in JavaScript (and the HTML that gets downloaded by bots is mostly empty), it seems that they’re a no-go if you want your websites to be indexed in search engines or even parsed by bots in general.
In this article, I will talk mostly about Vue.js, since it is the framework I’ve used most, and with which I have direct experiences in terms of indexing by the search engines on major projects, but I can assume that most of what I will cover is valid for other frameworks, too.
Replacing jQuery With Vue.js
Did you know that you can incorporate Vue into your project the same way that you would incorporate jQuery — with no build step necessary? Read a related article →
Some Background On The Problem
How Indexing Works
For your website to be indexed by Google, it needs to be crawled by Googlebot (an automated indexing software that visits your website and saves the contents of pages to its index) following links within each page. Googlebot also looks for special Sitemap XML files in websites to find pages that might not be linked correctly from your public site and to receive extra information on how often the pages in the website change and when they have last changed.
A Little Bit Of History
Until a few years ago (before 2009), Google used to index the content of a website’s HTML — excluding all the content created by JavaScript. It was common SEO knowledge that important links and content should not be written by JavaScript since it would not get indexed by Google, and it might cause a penalty for the website because Google might consider it “fake content” as if the website’s owner was trying to show users something different from what was shown to the search engines and trying to fool the latter.
It was very common practice by scammers to put a lot of SEO-friendly content in the HTML and hide it in JavaScript, for example. Google has always warned against this practice:
“Serving Googlebot different content than a normal user would see is considered cloaking, and would be against our Webmaster Guidelines.”
You could get penalized for this. In some cases, you could be penalized for serving different content to different user agents on the server side, but also for switching content via JavaScript after the page has loaded. I think this shows us that Google has been indexing websites executing JavaScript for a long time — at least for the sake of comparing the final HTML of the website (after JavaScript execution) and the raw HTML it was parsing for its indexes. But Googlebot did not execute JavaScript all the time, and Google was not using the JavaScript-generated content for indexing purposes.
Then, given the increased usage of AJAX to deliver dynamic content on websites, Google proposed an “AJAX crawling scheme” to help users index AJAX-based websites. It was very complicated; it basically required the website to produce a rendering of pages with AJAX content included. When requested by Google, the server would provide a version of the page with all (or most) of the content that would have been generated dynamically by JavaScript included in the HTML page — pre-rendered as an HTML Snapshot of the content. This process of having a server-side solution deliver content that was (for all other purposes) meant to be generated client-side, implied that those wanting to have a site that heavily relied on JavaScript indexed in Google had to go through a lot of technical hassles.
For example, if the content read by AJAX came from an external web service, it was necessary to duplicate the same web service calls server-side, and to produce, server-side, the same HTML that would have been produced client-side by JavaScript — or at least a very similar one. This was very complicated because, before the advent of Node.js, it required to at least partially duplicate the same rendering logic in two different programming languages: JavaScript for the frontend, and PHP, Java, Python, Ruby, and so on, on the backend. This is called “server-side rendering”, and it could lead to maintenance hell: if you made important changes to how you were rendering content in the frontend you had to duplicate those changes on the backend.
The only alternative to avoid duplicating the logic was to parse your own site with a browser executing JavaScript and save the end results to your server and serve those to Googlebot. This is sort of similar to what is now called “pre-rendering”.
Google (with its AJAX crawling scheme) also guaranteed that you would avoid penalties due to the fact that in this case you were serving different content to Googlebot and to the user. However, since 2015, Google has deprecated that practice with an official blog post that told website managers the following:
“Today, as long as you’re not blocking Googlebot from crawling your JavaScript or CSS files, we are generally able to render and understand your web pages like modern browsers.”
What this told us was not that Googlebot had suddenly acquired the capability of executing JavaScript when indexing web pages, since we know that it had done so for a very long time (at least to check for fake content and scams). Instead, it told us that the result of JavaScript execution would be indexed and used in SERPs.
This seems to imply that we don’t have to worry about providing Google with server-side rendered HTML anymore. However, we see all sorts of tools for server-side rendering and pre-rendering made available for JavaScript frameworks, it seems this is not the case. Also, when dealing with SEO agencies on big projects, pre-rendering seems to be considered mandatory. How come?
How Does Google Actually Index Pages Created With Front-End Frameworks?
The Experiment
In order to see what Google actually indexes in websites that have been created with a front-end framework, I built a little experiment. It does not cover all use cases, but it is at least a means to find out more about Google’s behavior. I built a small website with Vue.js and had different parts of text rendered differently.
The website’s contents are taken from the description of the book Infinite Jest by David Foster Wallace in the Infinite Jest Wiki (thanks guys!). There are a couple of introductory texts for the whole book, and a list of characters with their individual biography:
- Some text in the static HTML, outside of the Vue.js main container;
- Some text is rendered immediately by Vue.js because it is contained in variables which are already present in the application’s code: they are defined in the component’s
dataobject; - #Some text is rendered by Vue.js from the
dataobject, but with a delay of 300ms; - The character bios come from a set of rest APIs, which I’ve built on purpose using Sandbox. Since I was assuming that Google would execute the website’s code and stop after some time to take a snapshot of the current state of the page, I set each web service to respond with an incremental delay, the first with 0ms, the second with 300ms, the third with 600ms and so on up to 2700ms.
Each character bio is shortened and contains a link to a sub-page, which is available only through Vue.js (URLs are generated by Vue.js using the history API), but not server-side (if you call the URL of the page directly, you get no response from the server), to check if those got indexed too. I assumed that these would not get indexed, since they are not proper links which render server-side, and there’s no way that Google can direct users to those links directly. But I just wanted to check.
I published this little test site to my Github Pages and requested indexing — take a look.
The Results
The results of the experiment (concerning the homepage) are the following:
- The contents which are already in the static HTML content get indexed by Google (which is rather obvious);
- The contents which are generated by Vue in real-time always get indexed by Google;
- The contents which are generated by Vue, but rendered after 300ms get indexed as well;
- The contents which come from the web service, with some delay, might get indexed, but not always. I’ve checked Google’s indexing of the page in different moments, and the content which was inserted last (after a couple of seconds) sometimes got indexed, sometimes it didn’t. The content that gets rendered pretty quickly does get indexed most of the time, even if it comes from an asynchronous call to an external web service. This depends on Google having a render budget for each page and site, which depends on its internal algorithms, and it might vary wildly depending on the ranking of your site and the current state of Googlebot’s rendering queue. So you cannot rely on content coming from external web services to get indexed;
- The subpages (as they are not accessible as a direct link) do not get indexed as expected.
What does this experiment tell us? Basically, that Google does index dynamically generated content, even if comes from an external web service, but it is not guaranteed that content will be indexed if it “arrives too late”. I have had similar experiences with other real, production websites besides this experiment.
Competitive SEO
Okay, so the content gets indexed, but what this experiment doesn’t tell us is: will the content be ranked competitively? Will Google prefer a website with static content to a dynamically-generated website? This is not an easy question to answer.
From my experience, I can tell that dynamically-generated content can rank in the top positions of the SERPS. I’ve worked on the website for a new model of a major car company, launching a new website with a new third-level domain. The site was fully generated with Vue.js — with very little content in the static HTML besides <title> tags and meta descriptions.
The site started ranking for minor searches in the first few days after publication, and the text snippets in the SERPs reported words coming directly from the dynamic content.
Within three months it was ranking first for most searches related to that car model — which was relatively easy since it was hosted on an official domain belonging to the car’s manufacturer, and the domain was heavily linked from reputable websites.
But given the fact that we had had to face strong opposition from the SEO company that was in charge of the project, I think that the result was still remarkable.
Due to the tight deadlines and lack of time given for the project, we were going to publish the site without pre-rendering.
Animated Text
What Google does not index is heavily-animated text. The site of one of the companies I work with, Rabbit Hole Consulting, contains lots of text animations, which are performed while the user scrolls, and require the text to be split into several chunks across different tags.
The main texts in the website’s home page are not meant for search engine indexing since they are not optimized for SEO. They are not made of tech-speak and do not use keywords: they are only meant to accompany the user on a conceptual journey about the company. The text gets inserted dynamically when the user enters the various sections of the home page.
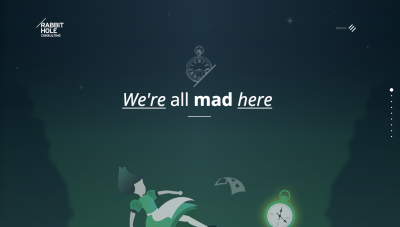
None of the texts in these sections of the website gets indexed by Google. In order to get Google to show something meaningful in the SERPs, we added some static text in the footer below the contact form, and this content does show as part of the page’s content in SERPs.
The text in the footer gets indexed and shown in SERPs, even though it is not immediately visible to the users unless they scroll to the bottom of the page and click on the “Questions” button to open the contact form. This confirms my opinion that content does get indexed even if it is not shown immediately to the user, as long as it is rendered soon to the HTML — as opposed to being rendered on-demand or after a long delay.
What About Pre-Rendering?
So, why all the fuss about pre-rendering — be it done server-side or at project compilation time? Is it really necessary? Although some frameworks, like Nuxt, make it much easier to perform, it is still no picnic, so the choice whether to set it up or not is not a light one.
I think it is not compulsory. It is certainly a requirement if a lot of the content you want to get indexed by Google comes from external web service and is not immediately available at rendering time, and might — in some unfortunate cases — not be available at all due to, for example, web service downtime. If during Googlebot’s visits some of your content arrives too slowly, then it might not be indexed. If Googlebot indexes your page exactly at a moment in which you are performing maintenance on your web services, it might not index any dynamic content at all.
Furthermore, I have no proof of ranking differences between static content and dynamically-generated content. That might require another experiment. I think that it is very likely that, if content comes from external web service and does not load immediately, it might impact on Google’s perception of your site’s performance, which is a very important factor for ranking.
Recommended reading: How Mobile Web Design Affects Local Search (And What To Do About It)
Other Considerations
Compatibility
Up until recently, Googlebot used a fairly old version of Chromium (the open-source project on which Google Chrome is based), namely version 41. This meant that some recent JavaScript or CSS features could not be rendered by Google correctly (e.g. IntersectionObserver, ES6 syntax, and so on).
Google has recently announced that it is now running the latest version of Chromium (74, at the time of writing) in Googlebot, and that the version will be updated regularly. The fact that Google was running Chromium 41 might have had big implications for sites which decided to disregard compatibility with IE11 and other old browsers.
You can see a comparison of Chromium 41 and Chromium 74’s support for features here, however, if your site was already polyfilling missing features to stay compatible with older browsers, there should have been no problem.
Always use polyfills since you never know which browser misses support for features that you think are commonplace. For example, Safari did not support a major and very useful new feature like IntersectionObserver until version 12.1, which came out in March 2019.
JavaScript Errors
If you rely on Googlebot executing your JavaScript to render vital content, then major JavaScript errors which could prevent the content from rendering must be avoided at all costs. While bots might parse and index HTML which is not perfectly valid (although it is always preferable to have valid HTML on any site!), if there is a JavaScript error that prevents the loading of some content, then there is no way Google will index that content.
In any case, if you rely on JavaScript to render vital content to your end users, then it is likely that you already have extensive unit tests to check for blocking errors of any kind. Keep in mind, however, that Javascript errors can arise from unpredictable scenarios, for example, in case of improper handling of errors on API responses.
It is better to have some real-time error-checking software in place (such as Sentry or LogRocket) which will alert you of any edge-case errors you might not pick during unit or manual testing. This adds to the complexity of relying on JavaScript for SEO content.
Other Search Engines
The other search engines do not work as well as Google with dynamic content. Bing does not seem to index dynamic content at all, nor do DuckDuckGo or Baidu. Probably those search engines lack the resources and computing power that Google has in spades.
Parsing a page with a headless browser and executing JavaScript for a couple of seconds to parse the rendered content is certainly more resource-heavy than just reading plain HTML. Or maybe these search engines have made the choice not to scan dynamic content for some other reasons. Whatever the cause of this, if your project needs to support any of those search engines, you need to set up pre-rendering.
Note: To get more information on other search engines’ rendering capabilities, you can check this article by Bartosz Góralewicz. It is a bit old, but according to my experience, it is still valid.
Other Bots
Remember that your site will be visited by other bots as well. The most important examples are Twitter, Facebook, and other social media bots that need to fetch meta information about your pages in order to show a preview of your page when it is linked by their users. These bots will not index dynamic content, and will only show the meta information that they find in the static HTML. This leads us to the next consideration.
Subpages
If your site is a so-called “One Page website”, and all the relevant content is located in one main HTML, you will have no problem having that content indexed by Google. However, if you need Google to index and show any secondary page on the website, you will still need to create static HTML for each of those — even if you rely on your JavaScript Framework to check the current URL and provide the relevant content to put in that page. My advice, in this case, is to create server-side (or static) pages that at least provide the correct title tag and meta description/information.
Conclusions
The conclusions I’ve come to while researching this article are the following:
- If you only target Google, it is not mandatory to use pre-rendering to have your site fully indexed, however:
- You should not rely on third-party web services for content that needs to be indexed, especially if they don’t reply quickly.
- The content you insert into your HTML immediately via Vue.js rendering does get indexed, but you shouldn’t use animated text or text that gets inserted in the DOM after user actions like scrolling, etc.
- Make sure you test for JavaScript errors as they could result on entire pages/sections not being indexed, or your site not being indexed at all.
- If your site has multiple pages, you still need to have some logic to create pages that, while relying on the same front-end rendering system as the home page, can be indexed by Google as individual URLs.
- If you need to have different description and preview images for social media between different pages, you will need to address this too, either server-side or by compiling static pages for each URL.
- If you need your site to perform on search engines other than Google, you will definitely need pre-rendering of some sort.
Acknowledgements: Many thanks to Sigrid Holzner of SEO Bavaria / Rabbit Hole Consulting for her review of this article.
Further Reading
- How To Deal With Big Tooling Upgrades In Large Organizations
- The Forensics Of React Server Components (RSCs)
- Adding Search To Your Site In 15 Minutes
- How To Monitor And Optimize Google Core Web Vitals



{kind=link}