Improve Your JavaScript Knowledge By Reading Source Code

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
 Try ProtoPie AI free →
Try ProtoPie AI free →
 Register Free Now
Register Free Now SurveyJS: White-Label Survey Solution for Your JS App
SurveyJS: White-Label Survey Solution for Your JS App

 Celebrating 10 million developers
Celebrating 10 million developersDo you remember the first time you dug deep into the source code of a library or framework you use frequently? For me, that moment came during my first job as a frontend developer three years ago.
We had just finished rewriting an internal legacy framework we used to create e-learning courses. At the beginning of the rewrite, we had spent time investigating a number of different solutions including Mithril, Inferno, Angular, React, Aurelia, Vue, and Polymer. As I was very much a beginner (I had just switched from journalism to web development), I remember feeling intimidated by the complexity of each framework and not understanding how each one worked.
My understanding grew when I began investigating our chosen framework, Mithril, in greater depth. Since then, my knowledge of JavaScript — and programming in general — has been greatly helped by the hours I have spent digging deep into the guts of the libraries I use daily either at work or in my own projects. In this post, I will share some of the ways you can take your favorite library or framework and use it as an educational tool.
The Benefits Of Reading Source Code
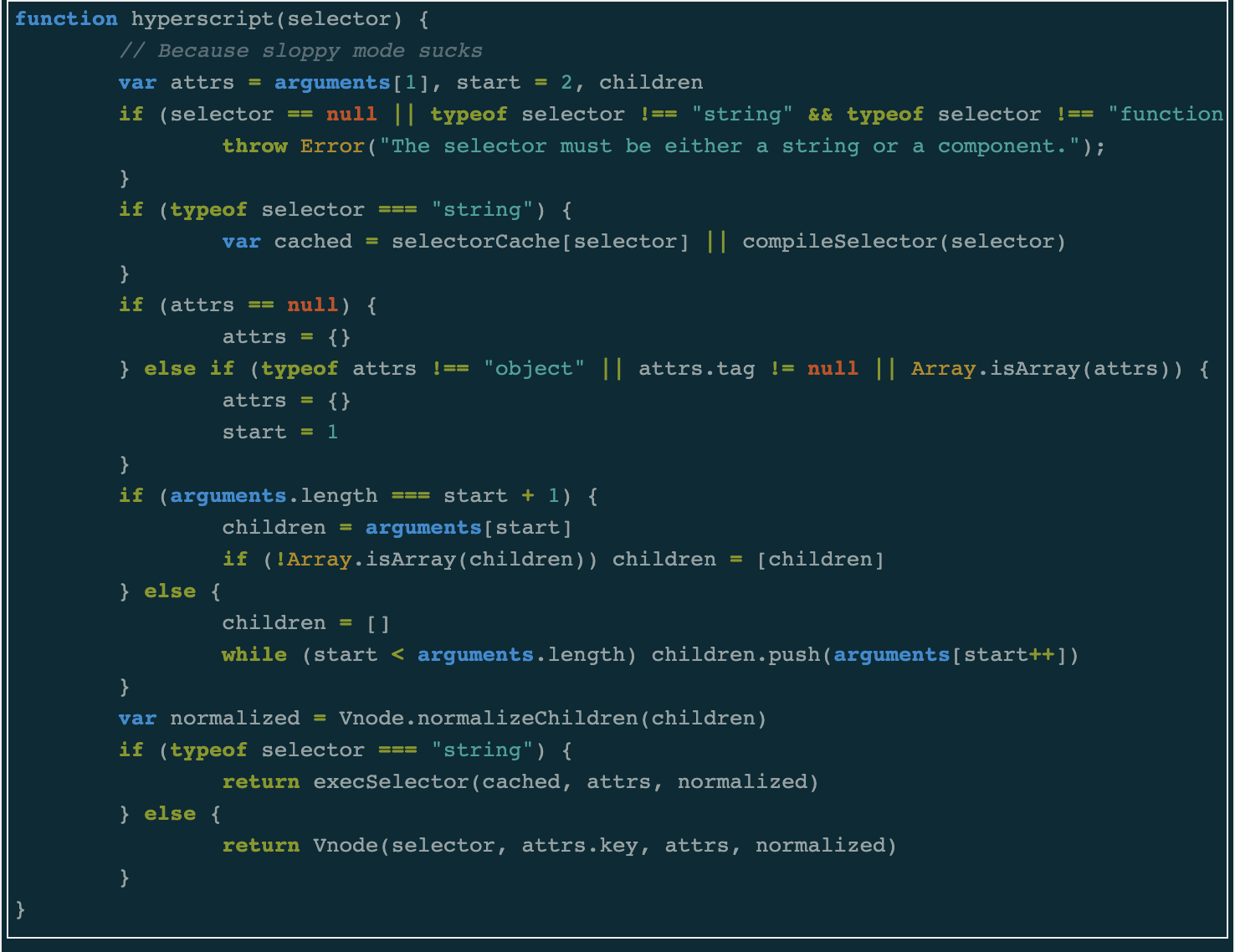
One of the major benefits of reading source code is the number of things you can learn. When I first looked into Mithril’s codebase, I had a vague idea of what the virtual DOM was. When I finished, I came away with the knowledge that the virtual DOM is a technique which involves creating a tree of objects that describe what your user interface should look like. That tree is then turned into DOM elements using DOM APIs such as document.createElement. Updates are performed by creating a new tree describing the future state of the user interface and then comparing it with objects from the old tree.
I had read about all of this in various articles and tutorials, and whilst it was helpful, being able to observe it at work in the context of an application we had shipped was very illuminating for me. It also taught me which questions to ask when comparing different frameworks. Instead of looking at GitHub stars, for example, I now knew to ask questions such as, “How does the way each framework performs updates affect performance and the user experience?”
Another benefit is an increase in your appreciation and understanding of good application architecture. Whilst most open-source projects generally follow the same structure with their repositories, each of them contains differences. Mithril’s structure is pretty flat and if you are familiar with its API, you can make educated guesses about the code in folders such as render, router and request. On the other hand, React’s structure reflects its new architecture. The maintainers have separated the module responsible for UI updates (react-reconciler) from the module responsible for rendering DOM elements (react-dom).
One of the benefits of this is that it is now easier for developers to write their own custom renderers by hooking into the react-reconciler package. Parcel, a module bundler I have been studying recently, also has a packages folder like React. The key module is named parcel-bundler and it contains the code responsible for creating bundles, spinning up the hot module server and the command-line tool.

Yet another benefit — which came as a welcome surprise to me — is you become more comfortable reading the official JavaScript specification which defines how the language works. The first time I read the spec was when I was investigating the difference between throw Error and throw new Error (spoiler alert — there is none). I looked into this because I noticed that Mithril used throw Error in the implementation of its m function and I wondered if there was a benefit to using it over throw new Error. Since then, I have also learnt that the logical operators && and || do not necessarily return booleans, found the rules which govern how the == equality operator coerces values and the reason Object.prototype.toString.call({}) returns '[object Object]'.
Techniques For Reading Source Code
There are many ways of approaching source code. I have found the easiest way to start is by selecting a method from your chosen library and documenting what happens when you call it. Do not document every single step but try to identify its overall flow and structure.
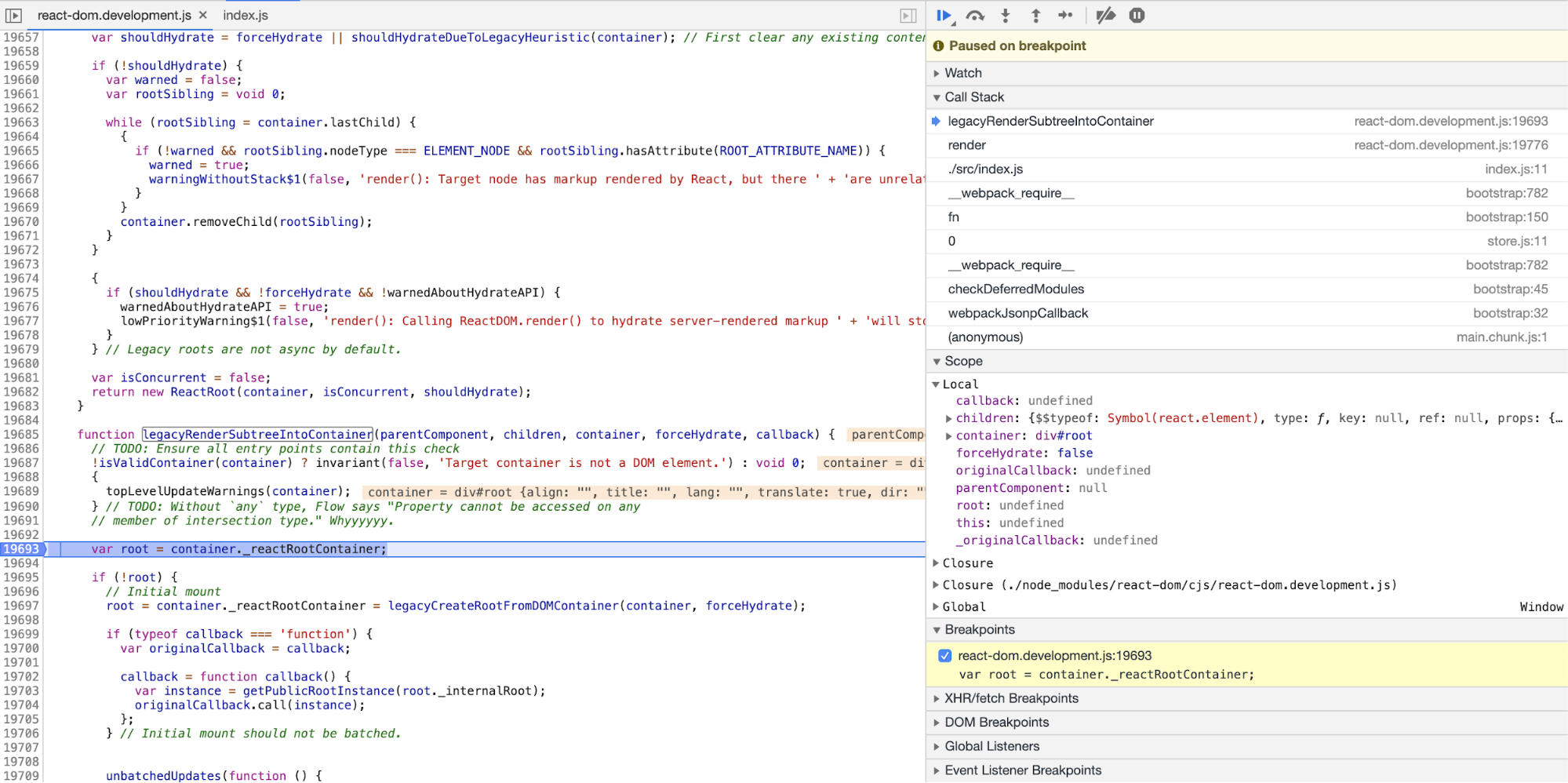
I did this recently with ReactDOM.render and consequently learned a lot about React Fiber and some of the reasons behind its implementation. Thankfully, as React is a popular framework, I came across a lot of articles written by other developers on the same issue and this sped up the process.
This deep dive also introduced me to the concepts of co-operative scheduling, the window.requestIdleCallback method and a real world example of linked lists (React handles updates by putting them in a queue which is a linked list of prioritised updates). When doing this, it is advisable to create a very basic application using the library. This makes it easier when debugging because you do not have to deal with the stack traces caused by other libraries.
If I am not doing an in-depth review, I will open up the /node_modules folder in a project I am working on or I will go to the GitHub repository. This usually happens when I come across a bug or interesting feature. When reading code on GitHub, make sure you are reading from the latest version. You can view the code from commits with the latest version tag by clicking the button used to change branches and select “tags”. Libraries and frameworks are forever undergoing changes so you do not want to learn about something which may be dropped in the next version.
Another less involved way of reading source code is what I like to call the ‘cursory glance’ method. Early on when I started reading code, I installed express.js, opened its /node_modules folder and went through its dependencies. If the README did not provide me with a satisfactory explanation, I read the source. Doing this led me to these interesting findings:
- Express depends on two modules which both merge objects but do so in very different ways.
merge-descriptorsonly adds properties directly found directly on the source object and it also merges non-enumerable properties whilstutils-mergeonly iterates over an object’s enumerable properties as well as those found in its prototype chain.merge-descriptorsusesObject.getOwnPropertyNames()andObject.getOwnPropertyDescriptor()whilstutils-mergeusesfor..in; - The
setprototypeofmodule provides a cross platform way of setting the prototype of an instantiated object; escape-htmlis a 78-line module for escaping a string of content so it can be interpolated in HTML content.
Whilst the findings are not likely to be useful immediately, having a general understanding of the dependencies used by your library or framework is useful.
When it comes to debugging front-end code, your browser’s debugging tools are your best friend. Among other things, they allow you to stop the program at any time and inspect its state, skip a function’s execution or step into or out of it. Sometimes this will not be immediately possible because the code has been minified. I tend to unminify it and copy the unminified code into the relevant file in the /node_modules folder.
Case Study: Redux’s Connect Function
React-Redux is a library used to manage the state of React applications. When dealing with popular libraries such as these, I start by searching for articles that have been written about its implementation. In doing so for this case study, I came across this article. This is another good thing about reading source code. The research phase usually leads you to informative articles such as this which only improve your own thinking and understanding.
connect is a React-Redux function which connects React components to an application’s Redux store. How? Well, according to the docs, it does the following:
“...returns a new, connected component class that wraps the component you passed in.”
After reading this, I would ask the following questions:
- Do I know any patterns or concepts in which functions take an input and then return that same input wrapped with additional functionality?
- If I know of any such patterns, how would I implement this based on the explanation given in the docs?
Usually, the next step would be to create a very basic example app which uses connect. However, on this occasion I opted to use the new React app we are building at Limejump because I wanted to understand connect within the context of an application which will eventually be going into a production environment.
The component I am focusing on looks like this:
class MarketContainer extends Component {
// code omitted for brevity
}
const mapDispatchToProps = dispatch => {
return {
updateSummary: (summary, start, today) => dispatch(updateSummary(summary, start, today))
}
}
export default connect(null, mapDispatchToProps)(MarketContainer);
It is a container component which wraps four smaller connected components. One of the first things you come across in the file which exports connect method is this comment: connect is a facade over connectAdvanced. Without going far we have our first learning moment: an opportunity to observe the facade design pattern in action. At the end of the file we see that connect exports an invocation of a function called createConnect. Its parameters are a bunch of default values which have been destructured like this:
export function createConnect({
connectHOC = connectAdvanced,
mapStateToPropsFactories = defaultMapStateToPropsFactories,
mapDispatchToPropsFactories = defaultMapDispatchToPropsFactories,
mergePropsFactories = defaultMergePropsFactories,
selectorFactory = defaultSelectorFactory
} = {})
Again, we come across another learning moment: exporting invoked functions and destructuring default function arguments. The destructuring part is a learning moment because had the code been written like this:
export function createConnect({
connectHOC = connectAdvanced,
mapStateToPropsFactories = defaultMapStateToPropsFactories,
mapDispatchToPropsFactories = defaultMapDispatchToPropsFactories,
mergePropsFactories = defaultMergePropsFactories,
selectorFactory = defaultSelectorFactory
})
It would have resulted in this error Uncaught TypeError: Cannot destructure property 'connectHOC' of 'undefined' or 'null'. This is because the function has no default argument to fall back on.
Note: For more on this, you can read David Walsh’s article. Some learning moments may seem trivial, depending on your knowledge of the language, and so it might be better to focus on things you have not seen before or need to learn more about.
createConnect itself does nothing in its function body. It returns a function called connect, the one I used here:
export default connect(null, mapDispatchToProps)(MarketContainer)
It takes four arguments, all optional, and the first three arguments each go through a match function which helps define their behaviour according to whether the arguments are present and their value type. Now, because the second argument provided to match is one of three functions imported into connect, I have to decide which thread to follow.
There are learning moments with the proxy function used to wrap the first argument to connect if those arguments are functions, the isPlainObject utility used to check for plain objects or the warning module which reveals how you can set your debugger to break on all exceptions. After the match functions, we come to connectHOC, the function which takes our React component and connects it to Redux. It is another function invocation which returns wrapWithConnect, the function which actually handles connecting the component to the store.
Looking at connectHOC’s implementation, I can appreciate why it needs connect to hide its implementation details. It is the heart of React-Redux and contains logic which does not need to be exposed via connect. Even though I will end the deep dive here, had I continued, this would have been the perfect time to consult the reference material I found earlier as it contains an incredibly detailed explanation of the codebase.
Summary
Reading source code is difficult at first but as with anything, it becomes easier with time. The goal is not to understand everything but to come away with a different perspective and new knowledge. The key is to be deliberate about the entire process and intensely curious about everything.
For example, I found the isPlainObject function interesting because it uses this if (typeof obj !== 'object' || obj === null) return false to make sure the given argument is a plain object. When I first read its implementation, I wondered why it did not use Object.prototype.toString.call(opts) !== '[object Object]', which is less code and distinguishes between objects and object sub types such as the Date object. However, reading the next line revealed that in the extremely unlikely event that a developer using connect returns a Date object, for example, this will be handled by the Object.getPrototypeOf(obj) === null check.
Another bit of intrigue in isPlainObject is this code:
while (Object.getPrototypeOf(baseProto) !== null) {
baseProto = Object.getPrototypeOf(baseProto)
}
Some Google searching led me to this StackOverflow thread and the Redux issue explaining how that code handles cases such as checking against objects which originate from an iFrame.
Useful Links On Reading Source Code
- “How To Reverse Engineer Frameworks,” Max Koretskyi, Medium
- “How To Read Code,” Aria Stewart, GitHub
Further Reading
- Switching It Up With HTML’s Latest Control
- The Forensics Of React Server Components (RSCs)
- Transforming The Relationship Between Designers And Developers
- Penpot’s CSS Grid Layout: Designing With Superpowers


