Front-End Performance 2021: Defining The Environment

Email Newsletter
Weekly tips on front-end & UX.
Trusted by 182,000+ folks.
This guide has been kindly supported by our friends at LogRocket, a service that combines frontend performance monitoring, session replay, and product analytics to help you build better customer experiences. LogRocket tracks key metrics, incl. DOM complete, time to first byte, first input delay, client CPU and memory usage. Get a free trial of LogRocket today.
Table Of Contents
- Getting Ready: Planning And Metrics
- Setting Realistic Goals
- Defining The Environment
- Assets Optimizations
- Build Optimizations
- Delivery Optimizations
- Networking, HTTP/2, HTTP/3
- Testing And Monitoring
- Quick Wins
- Everything on one page
- Download The Checklist (PDF, Apple Pages, MS Word)
- Subscribe to our email newsletter to not miss the next guides.
Defining The Environment
- Choose and set up your build tools.
Don’t pay too much attention to what’s supposedly cool these days. Stick to your environment for building, be it Grunt, Gulp, Webpack, Parcel, or a combination of tools. As long as you are getting results you need and you have no issues maintaining your build process, you’re doing just fine.Among the build tools, Rollup keeps gaining traction, so does Snowpack, but Webpack seems to be the most established one, with literally hundreds of plugins available to optimize the size of your builds. Watch out for the Webpack Roadmap 2021.
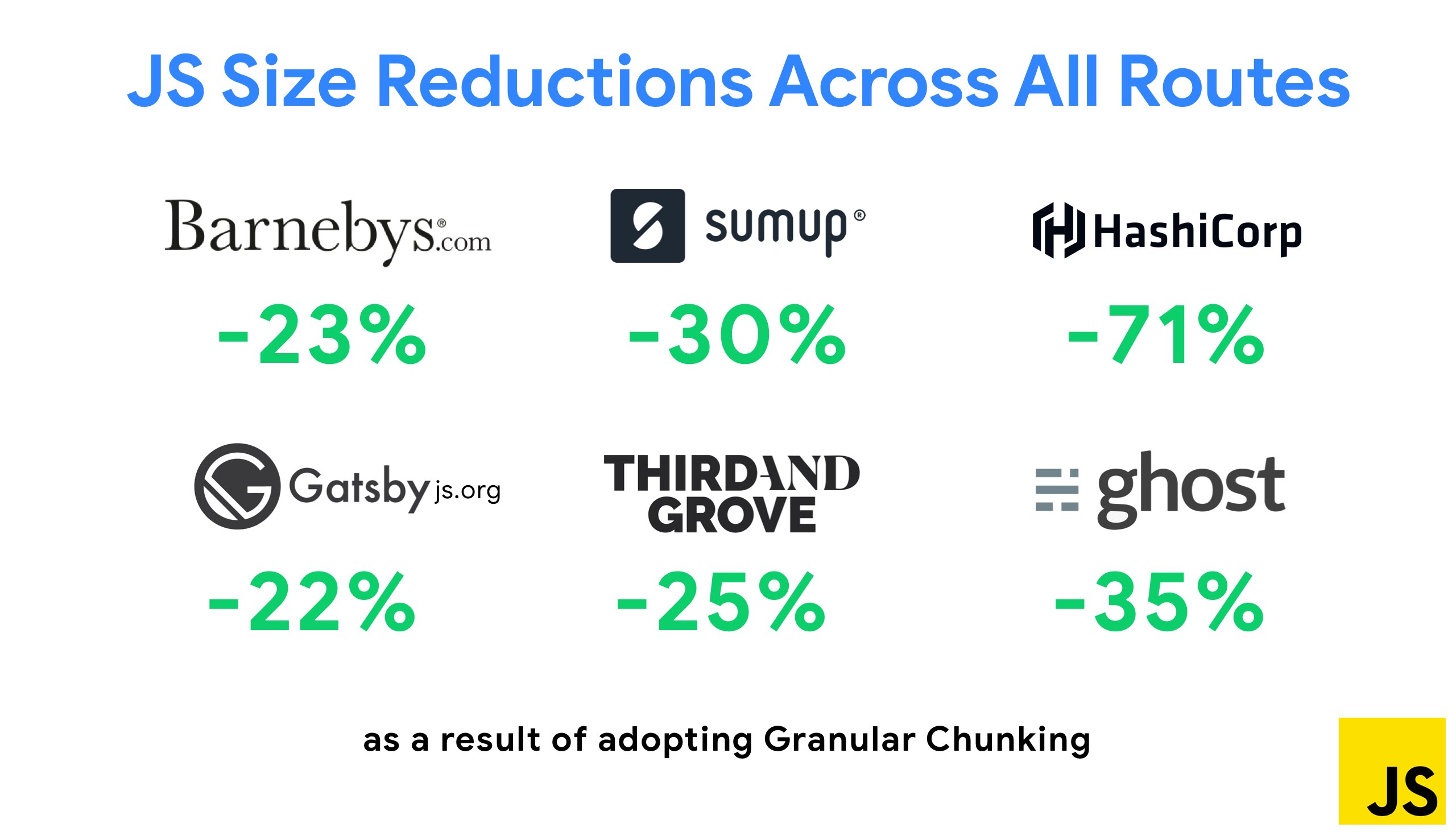
One of the most notable strategies that appeared recently is Granular chunking with Webpack in Next.js and Gatsby to minimize duplicate code. By default, modules that aren't shared in every entry point can be requested for routes that do not use it. This ends up becoming an overhead as more code is downloaded than necessary. With granular chunking in Next.js, we can use a server-side build manifest file to determine which outputted chunks are used by different entry points.

To reduce duplicate code in Webpack projects, we can use granular chunking, enabled in Next.js and Gatsby by default. Image credit: Addy Osmani. (Large preview) With SplitChunksPlugin, multiple split chunks are created depending on a number of conditions to prevent fetching duplicated code across multiple routes. This improves page load time and caching during navigations. Shipped in Next.js 9.2 and in Gatsby v2.20.7.
Getting started with Webpack can be tough though. So if you want to dive into Webpack, there are some great resources out there:
- Webpack documentation — obviously — is a good starting point, and so are Webpack — The Confusing Bits by Raja Rao and An Annotated Webpack Config by Andrew Welch.
- Sean Larkin has a free course on Webpack: The Core Concepts and Jeffrey Way has released a fantastic free course on Webpack for everyone. Both of them are great introductions for diving into Webpack.
- Webpack Fundamentals is a very comprehensive 4h course with Sean Larkin, released by FrontendMasters.
- Webpack examples has hundreds of ready-to-use Webpack configurations, categorized by topic and purpose. Bonus: there is also a Webpack config configurator that generates a basic configuration file.
- awesome-webpack is a curated list of useful Webpack resources, libraries and tools, including articles, videos, courses, books and examples for Angular, React and framework-agnostic projects.
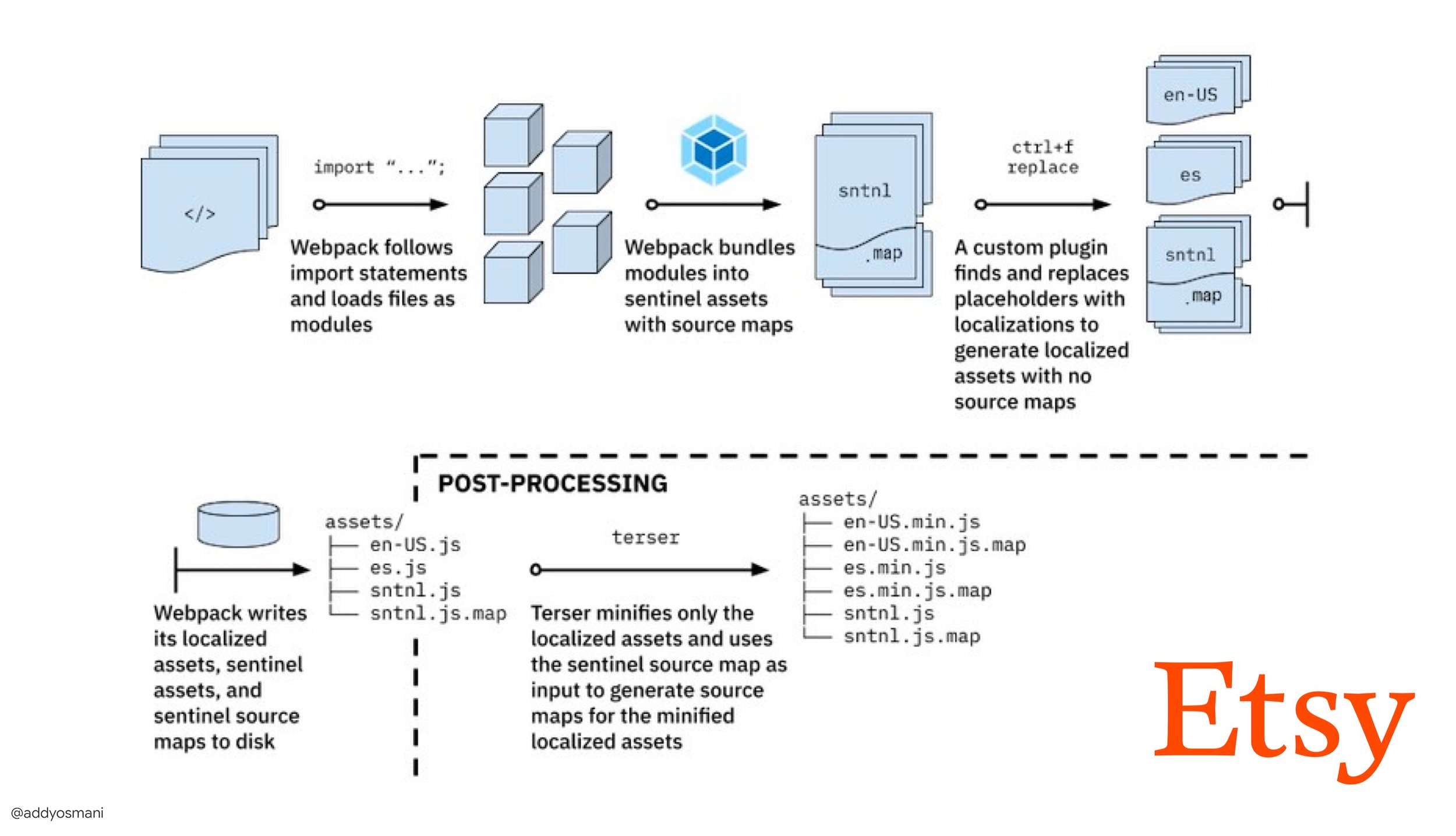
- The journey to fast production asset builds with Webpack is Etsy’s case study on how the team switched from using a RequireJS-based JavaScript build system to using Webpack and how they optimized theird builds, managing over 13,200 assets in 4 mins on average.
- Webpack performance tips is a goldmine thread by Ivan Akulov, featuring many performance-focused tips, including the ones focused specifically on Webpack.
- awesome-webpack-perf is a goldmine GitHub repo with useful Webpack tools and plugins for performance. Also maintained by Ivan Akulov.
- Use progressive enhancement as a default.
Still, after all these years, keeping progressive enhancement as the guiding principle of your front-end architecture and deployment is a safe bet. Design and build the core experience first, and then enhance the experience with advanced features for capable browsers, creating resilient experiences. If your website runs fast on a slow machine with a poor screen in a poor browser on a sub-optimal network, then it will only run faster on a fast machine with a good browser on a decent network.In fact, with adaptive module serving, we seem to be taking progressive enhancement to another level, serving "lite" core experiences to low-end devices, and enhancing with more sophisticated features for high-end devices. Progressive enhancement isn’t likely to fade away any time soon.
- Choose a strong performance baseline.
With so many unknowns impacting loading — the network, thermal throttling, cache eviction, third-party scripts, parser blocking patterns, disk I/O, IPC latency, installed extensions, antivirus software and firewalls, background CPU tasks, hardware and memory constraints, differences in L2/L3 caching, RTTS — JavaScript has the heaviest cost of the experience, next to web fonts blocking rendering by default and images often consuming too much memory. With the performance bottlenecks moving away from the server to the client, as developers, we have to consider all of these unknowns in much more detail.With a 170KB budget that already contains the critical-path HTML/CSS/JavaScript, router, state management, utilities, framework, and the application logic, we have to thoroughly examine network transfer cost, the parse/compile-time and the runtime cost of the framework of our choice. Luckily, we’ve seen a huge improvement over the last few years in how fast browsers can parse and compile scripts. Yet the execution of JavaScript is still the main bottleneck, so paying close attention to script execution time and network can be impactful.
Tim Kadlec has conduct a fantastic research on the performance of modern frameworks, and summarized them in the article "JavaScript frameworks have a cost". We often speak about the impact of standalone frameworks, but as Tim notes, in practice, it's not uncommon to have multiple frameworks in use. Perhaps an older version of jQuery that's being slowly migrated to a modern framework, along with a few legacy applications using an older version of Angular. So it's more reasonable to explore the cumulative cost of JavaScript bytes and CPU execution time that can easily make user experiences barely usable, even on high-end devices.
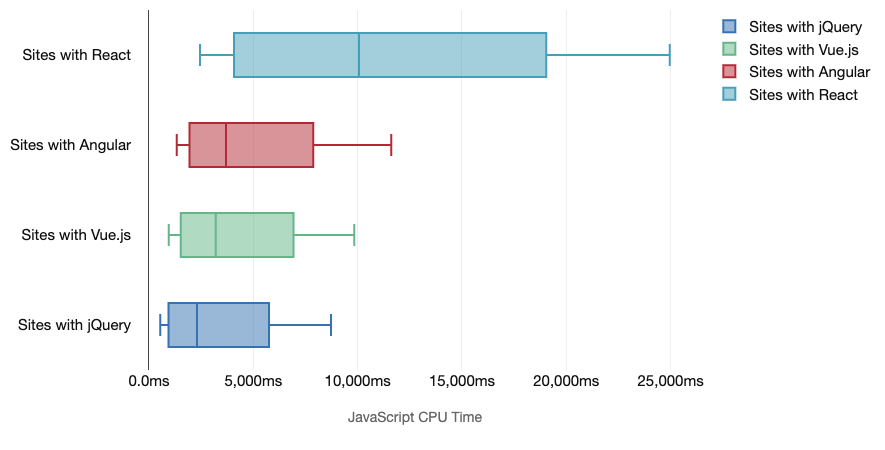
In general, modern frameworks aren't prioritizing less powerful devices, so the experiences on a phone and on desktop will often be dramatically different in terms of performances. According to research, sites with React or Angular spend more time on the CPU than others (which of course isn’t necessarily to say that React is more expensive on the CPU than Vue.js).
According to Tim, one thing is obvious: "if you’re using a framework to build your site, you’re making a trade-off in terms of initial performance — even in the best of scenarios."
- Evaluate frameworks and dependencies.
Now, not every project needs a framework and not every page of a single-page-application needs to load a framework. In Netflix’s case, "removing React, several libraries and the corresponding app code from the client-side reduced the total amount of JavaScript by over 200KB, causing an over-50% reduction in Netflix’s Time-to-Interactivity for the logged-out homepage." The team then utilized the time spent by users on the landing page to prefetch React for subsequent pages that users were likely to land on (read on for details).So what if you remove an existing framework on critical pages altogether? With Gatsby, you can check gatsby-plugin-no-javascript that removes all JavaScript files created by Gatsby from the static HTML files. On Vercel, you can also allow disabling runtime JavaScript in production for certain pages (experimental).
Once a framework is chosen, we’ll be staying with it for at least a few years, so if we need to use one, we need make sure our choice is informed and well considered — and that goes especially for key performance metrics that we care about.
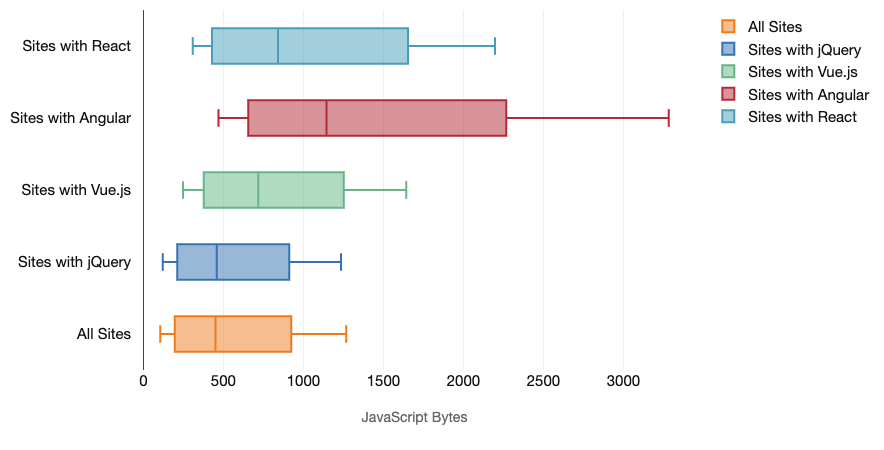
Data shows that, by default, frameworks are quite expensive: 58.6% of React pages ship over 1 MB of JavaScript, and 36% of Vue.js page loads have a First Contentful Paint of <1.5s. According to a study by Ankur Sethi, "your React application will never load faster than about 1.1 seconds on an average phone in India, no matter how much you optimize it. Your Angular app will always take at least 2.7 seconds to boot up. The users of your Vue app will need to wait at least 1 second before they can start using it." You might not be targeting India as your primary market anyway, but users accessing your site with suboptimal network conditions will have a comparable experience.
Of course it is possible to make SPAs fast, but they aren't fast out of the box, so we need to account for the time and effort required to make and keep them fast. It's probably going to be easier by choosing a lightweight baseline performance cost early on.
So how do we choose a framework? It’s a good idea to consider at least the total cost on size + initial execution times before choosing an option; lightweight options such as Preact, Inferno, Vue, Svelte, Alpine or Polymer can get the job done just fine. The size of your baseline will define the constraints for your application’s code.
As noted by Seb Markbåge, a good way to measure start-up costs for frameworks is to first render a view, then delete it and then render again as it can tell you how the framework scales. The first render tends to warm up a bunch of lazily compiled code, which a larger tree can benefit from when it scales. The second render is basically an emulation of how code reuse on a page affects the performance characteristics as the page grows in complexity.
You could go as far as evaluating your candidates (or any JavaScript library in general) on Sacha Greif’s 12-point scale scoring system by exploring features, accessibility, stability, performance, package ecosystem, community, learning curve, documentation, tooling, track record, team, compatibility, security for example.
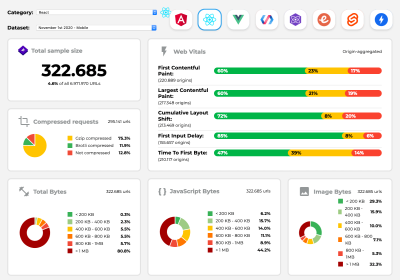
Perf Track tracks framework performance at scale. (Large preview) You can also rely on data collected on the web over a longer period of time. For example, Perf Track tracks framework performance at scale, showing origin-aggregated Core Web Vitals scores for websites built in Angular, React, Vue, Polymer, Preact, Ember, Svelte and AMP. You can even specify and compare websites built with Gatsby, Next.js or Create React App, as well as websites built with Nuxt.js (Vue) or Sapper (Svelte).
A good starting point is to choose a good default stack for your application. Gatsby (React), Next.js (React), Vuepress (Vue), Preact CLI, and PWA Starter Kit provide reasonable defaults for fast loading out of the box on average mobile hardware. Also, take a look at web.dev framework-specific performance guidance for React and Angular (thanks, Phillip!).
And perhaps you could take a slightly more refreshing approach to building single-page applications altogether — Turbolinks, a 15KB JavaScript-library that uses HTML instead of JSON to render views. So when you follow a link, Turbolinks automatically fetches the page, swaps in its `
`, and merges its ``, all without incurring the cost of a full page load. You can check quick detils and full documentation about the stack (Hotwire).
- Client-side rendering or server-side rendering? Both!
That’s a quite heated conversation to have. The ultimate approach would be to set up some sort of progressive booting: Use server-side rendering to get a quick First Contenful Paint, but also include some minimal necessary JavaScript to keep the time-to-interactive close to the First Contentful Paint. If JavaScript is coming too late after the FCP, the browser will lock up the main thread while parsing, compiling and executing late-discovered JavaScript, hence handcuffing the interactivity of site or application.To avoid it, always break up the execution of functions into separate, asynchronous tasks, and where possible use
requestIdleCallback. Consider lazy loading parts of the UI using WebPack’s dynamicimport()support, avoiding the load, parse, and compile cost until users really need them (thanks Addy!).As mentioned above, Time to Interactive (TTI) tells us the time between navigation and interactivity. In detail, the metric is defined by looking at the first five-second window after the initial content is rendered, in which no JavaScript tasks take longer than 50ms (Long Tasks). If a task over 50ms occurs, the search for a five-second window starts over. As a result, the browser will first assume that it reached Interactive, just to switch to Frozen, just to eventually switch back to Interactive.
Once we reached Interactive, we can then — either on demand or as time allows — boot non-essential parts of the app. Unfortunately, as Paul Lewis noticed, frameworks typically have no simple concept of priority that can be surfaced to developers, and hence progressive booting isn’t easy to implement with most libraries and frameworks.
Still, we are getting there. These days there are a couple of choices we can explore, and Houssein Djirdeh and Jason Miller provide an excellent overview of these options in their talk on Rendering on the Web and Jason's and Addy's write-up on Modern Front-End Architectures. The overview below is based on their stellar work.
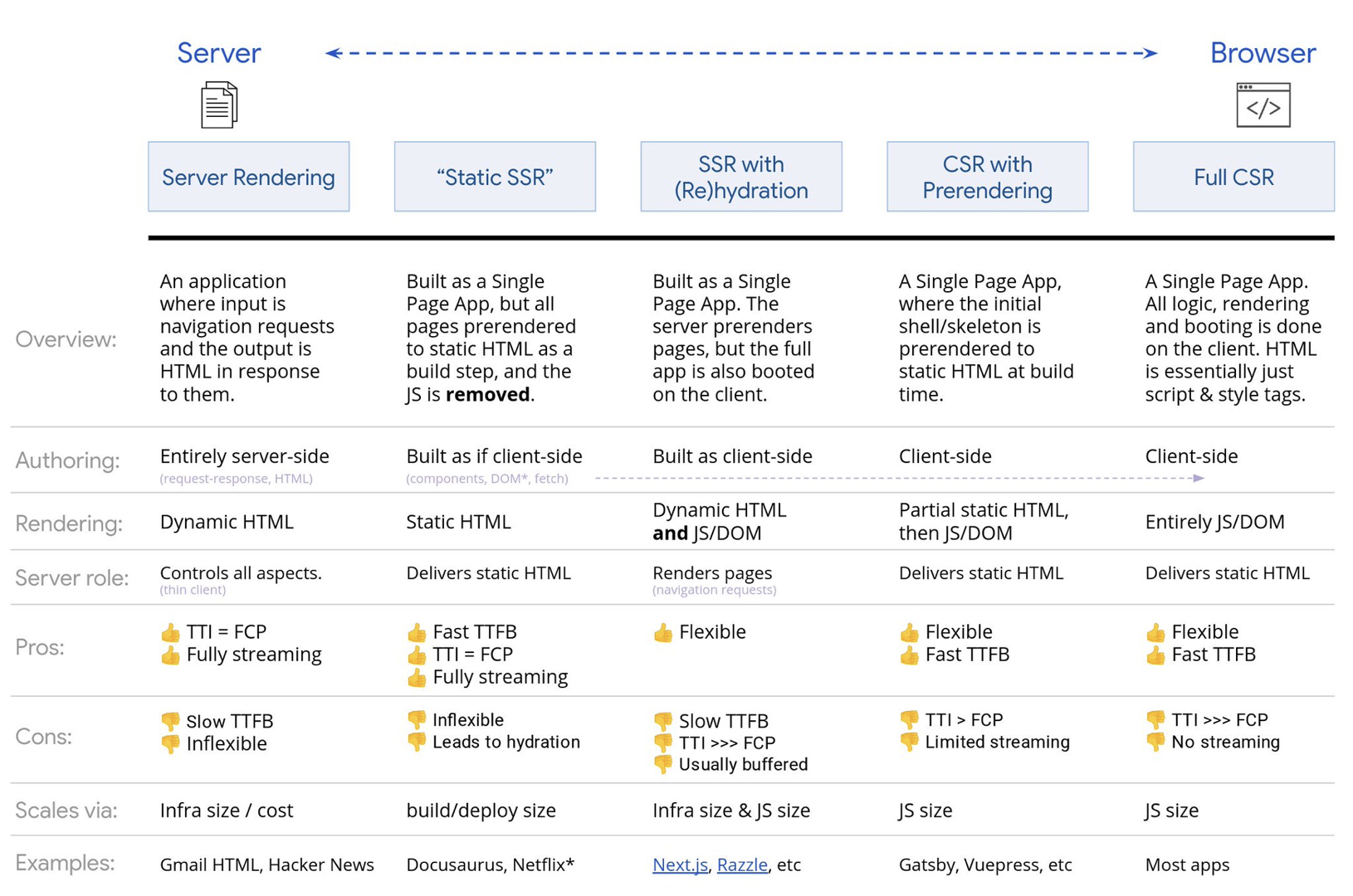
- Full Server-Side Rendering (SSR)
In classic SSR, such as WordPress, all requests are handled entirely on the server. The requested content is returned as a finished HTML page and browsers can render it right away. Hence, SSR-apps can’t really make use of the DOM APIs, for example. The gap between First Contentful Paint and Time to Interactive is usually small, and the page can be rendered right away as HTML is being streamed to the browser.This avoids additional round-trips for data fetching and templating on the client, since it’s handled before the browser gets a response. However, we end up with longer server think time and consequently Time To First Byte and we don’t make use of responsive and rich features of modern applications.
- Static Rendering
We build out the product as a single page application, but all pages are prerendered to static HTML with minimal JavaScript as a build step. That means that with static rendering, we produce individual HTML files for every possible URL ahead of time, which is something not many applications can afford. But because the HTML for a page doesn't have to be generated on the fly, we can achieve a consistently fast Time To First Byte. Thus, we can display a landing page quickly and then prefetch a SPA-framework for subsequent pages. Netflix has adopted this approach decreasing loading and Time-to-Interactive by 50%. - Server-Side Rendering With (Re)Hydration (Universal Rendering, SSR + CSR)
We can try to use the best of both worlds — the SSR and the CSR approches. With hydration in the mix, the HTML page returned from the server also contains a script that loads a fully-fledged client-side application. Ideally, that achieve a fast First Contentful Paint (like SSR) and then continue rendering with (re)hydration. Unfortunately, that's rarely the case. More often, the page does look ready but it can't respond to user's input, producing rage clicks and abandonments.With React, we can use
ReactDOMServermodule on a Node server like Express, and then call therenderToStringmethod to render the top level components as a static HTML string.With Vue.js, we can use the vue-server-renderer to render a Vue instance into HTML using
renderToString. In Angular, we can use@nguniversalto turn client requests into fully server-rendered HTML pages. A fully server-rendered experience can also be achieved out of the box with Next.js (React) or Nuxt.js (Vue).The approach has its downsides. As a result, we do gain full flexibility of client-side apps while providing faster server-side rendering, but we also end up with a longer gap between First Contentful Paint and Time To Interactive and increased First Input Delay. Rehydration is very expensive, and usually this strategy alone will not be good enough as it heavily delays Time To Interactive.
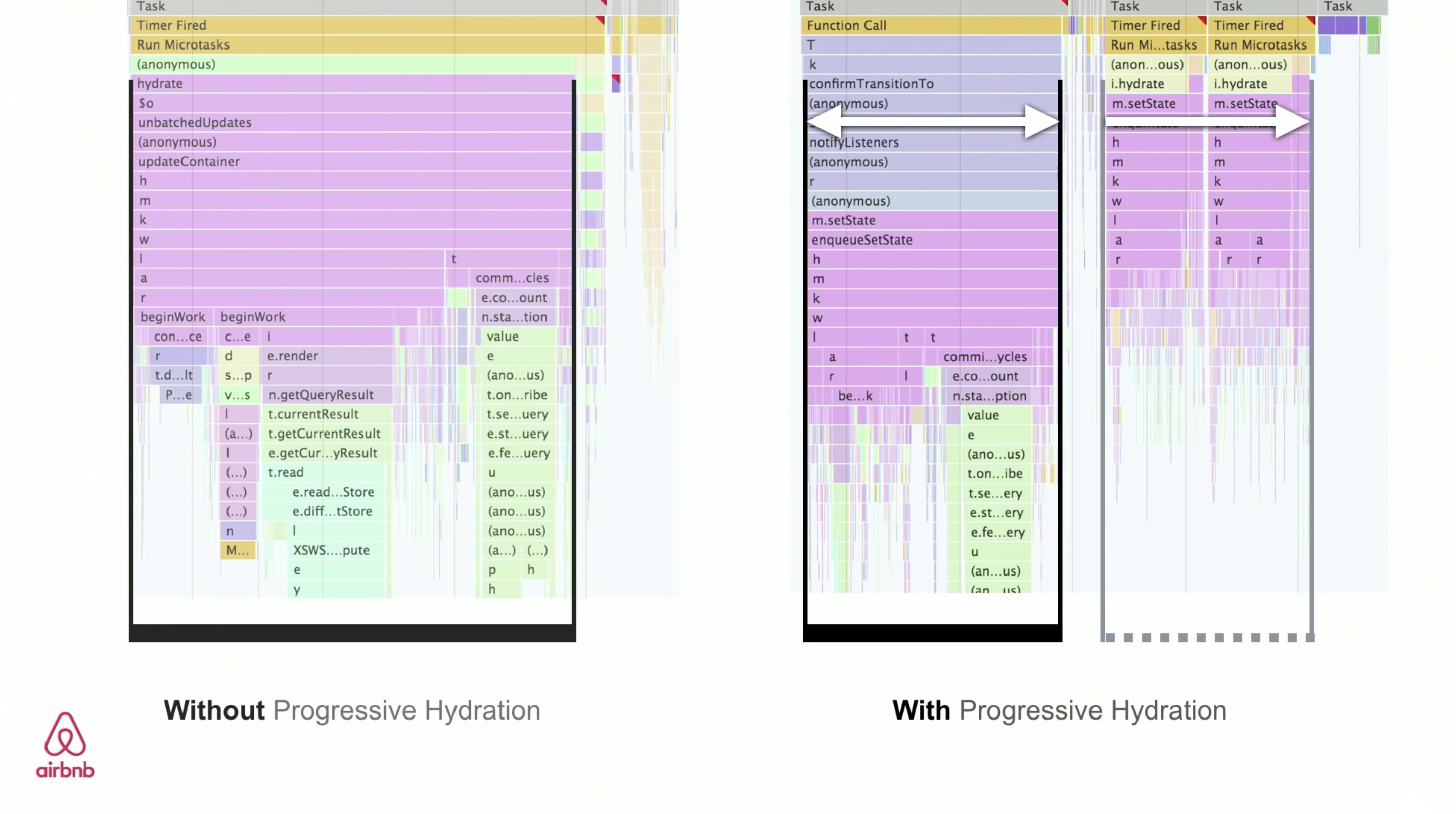
- Streaming Server-Side Rendering With Progressive Hydration (SSR + CSR)
To minimize the gap between Time To Interactive and First Contentful Paint, we render multiple requests at once and send down content in chunks as they get generated. So we don’t have to wait for the full string of HTML before sending content to the browser, and hence improve Time To First Byte.In React, instead of
renderToString(), we can use renderToNodeStream() to pipe the response and send the HTML down in chunks. In Vue, we can use renderToStream() that can be piped and streamed. With React Suspense, we might use asynchronous rendering for that purpose, too.On the client-side, rather than booting the entire application at once, we boot up components progressively. Sections of the applications are first broken down into standalone scripts with code splitting, and then hydrated gradually (in order of our priorities). In fact, we can hydrate critical components first, while the rest could be hydrated later. The role of client-side and server-side rendering can then be defined differently per component. We can then also defer hydration of some components until they come into view, or are needed for user interaction, or when the browser is idle.
For Vue, Markus Oberlehner has published a guide on reducing Time To Interactive of SSR apps using hydration on user interaction as well as vue-lazy-hydration, an early-stage plugin that enables component hydration on visibility or specific user interaction. The Angular team works on progressive hydration with Ivy Universal. You can implement partial hydration with Preact and Next.js, too.
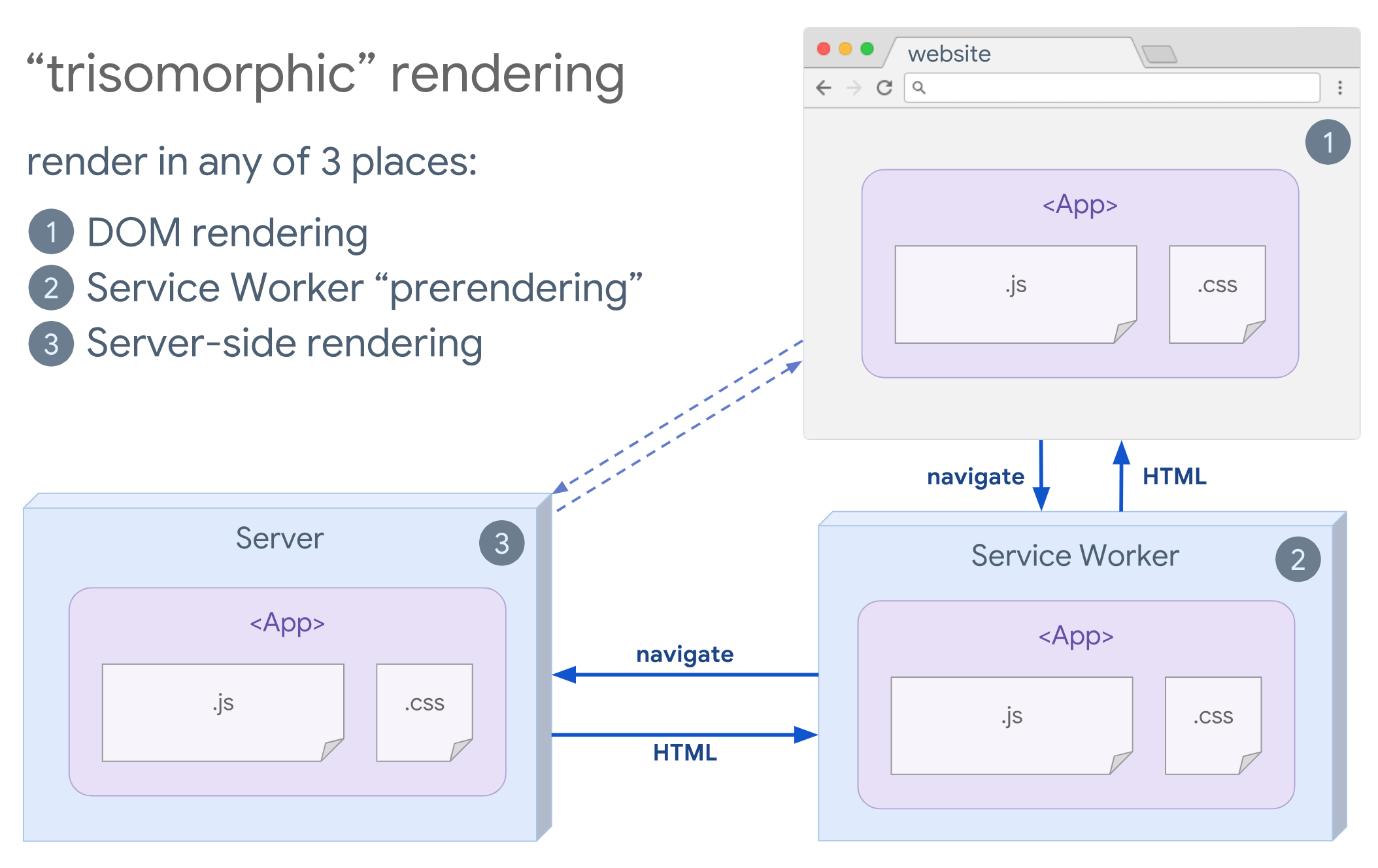
- Trisomorphic Rendering
With service workers in place, we can use streaming server rendering for initial/non-JS navigations, and then have the service worker taking on rendering of HTML for navigations after it has been installed. In that case, service worker prerenders content and enables SPA-style navigations for rendering new views in the same session. Works well when you can share the same templating and routing code between the server, client page, and service worker.
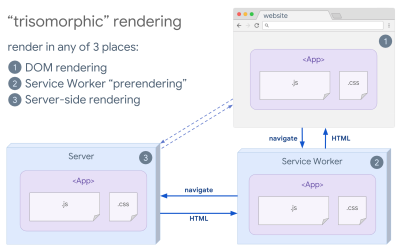
Trisomorphic rendering, with the same code rendering in any 3 places: on the server, in the DOM or in a service worker. (Image source: Google Developers) (Large preview) - CSR With Prerendering
Prerendering is similar to server-side rendering but rather than rendering pages on the server dynamically, we render the application to static HTML at build time. While static pages are fully interactive without much client-side JavaScript, prerendering works differently. Basically it captures the initial state of a client-side application as static HTML at build time, while with prerendering the application must be booted on the client for the pages to be interactive.With Next.js, we can use static HTML export by prerendering an app to static HTML. In Gatsby, an open source static site generator that uses React, uses
renderToStaticMarkupmethod instead ofrenderToStringmethod during builds, with main JS chunk being preloaded and future routes are prefetched, without DOM attributes that aren’t needed for simple static pages.For Vue, we can use Vuepress to achieve the same goal. You can also use prerender-loader with Webpack. Navi provides static rendering as well.
The result is a better Time To First Byte and First Contentful Paint, and we reduce the gap between Time To Interactive and First Contentful Paint. We can’t use the approach if the content is expected to change much. Plus, all URLs have to be known ahead of time to generate all the pages. So some components might be rendered using prerendering, but if we need something dynamic, we have to rely on the app to fetch the content.
- Full Client-Side Rendering (CSR)
All logic, rendering and booting are done on the client. The result is usually a huge gap between Time To Interactive and First Contentful Paint. As a result, applications often feel sluggish as the entire app has to be booted on the client to render anything.As JavaScript has a performance cost, as the amount of JavaScript grow with an application, aggressive code-splitting and deferring JavaScript will be absolutely necessarily to tame the impact of JavaScript. For such cases, a server-side rendering will usually be a better approach in case not much interactivity is required. If it's not an option, consider using The App Shell Model.
In general, SSR is faster than CSR. Yet still, it’s a quite frequent implementation for many apps out there.
So, client-side or server-side? In general, it’s a good idea to limit the use of fully client-side frameworks to pages that absolutely require them. For advanced applications, it’s not a good idea to rely on server-side rendering alone either. Both server-rendering and client-rendering are a disaster if done poorly.
Whether you are leaning towards CSR or SSR, make sure that you are rendering important pixels as soon as possible and minimize the gap between that rendering and Time To Interactive. Consider prerendering if your pages don’t change much, and defer the booting of frameworks if you can. Stream HTML in chunks with server-side rendering, and implement progressive hydration for client-side rendering — and hydrate on visibility, interaction or during idle time to get the best of both worlds.
- Full Server-Side Rendering (SSR)
- How much can we serve statically?
Whether you're working on a large application or a small site, it's worth considering what content could be served statically from a CDN (i.e. JAM Stack), rather than being generated dynamically on the fly. Even if you have thousands of products and hundreds of filters with plenty of personalization options, you might still want to serve your critical landing pages statically, and decouple these pages from the framework of your choice.There are plenty of static-site generators and the pages they generate are often very fast. The more content we can pre-build ahead of time instead of generating page views on a server or client at request time, the better performance we will achieve.
In Building Partially Hydrated, Progressively Enhanced Static Websites, Markus Oberlehner shows how to build out websites with a static site generator and an SPA, while achieving progressive enhancement and a minimal JavaScript bundle size. Markus uses Eleventy and Preact as his tools, and shows how to set up the tools, add partial hydration, lazy hydration, client entry file, configure Babel for Preact and bundle Preact with Rollup — from start to finish.
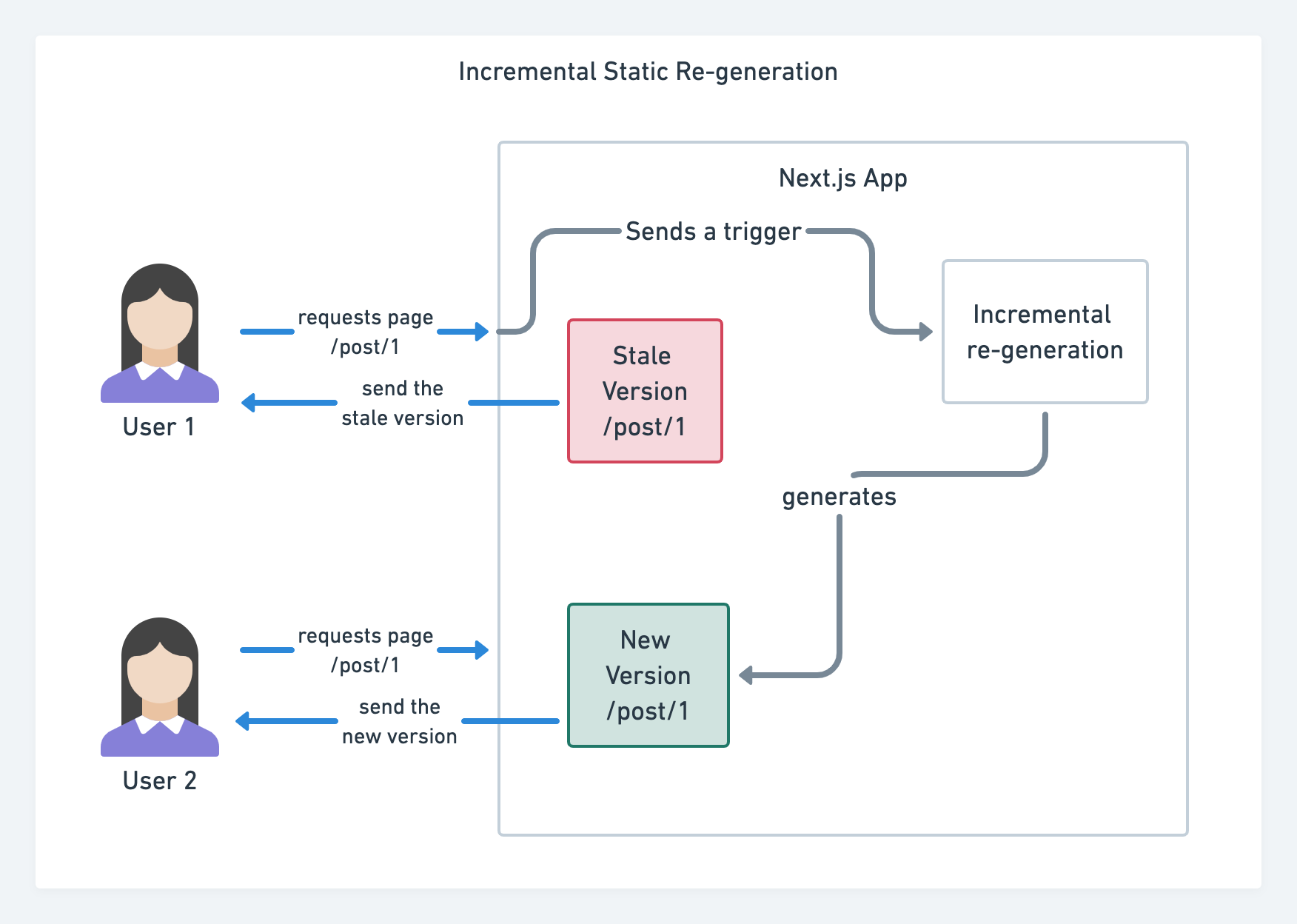
With JAMStack used on large sites these days, a new performance consideration appeared: the build time. In fact, building out even thousands of pages with every new deploy can take minutes, so it's promising to see incremental builds in Gatsby which improve build times by 60 times, with an integration into popular CMS solutions like WordPress, Contentful, Drupal, Netlify CMS and others.
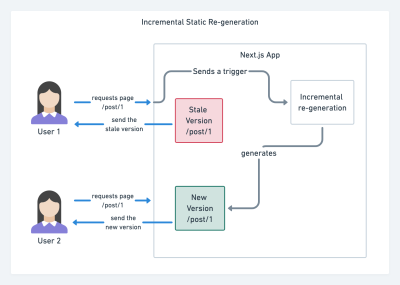
Incremental static regeneration with Next.js. (Image credit: Prisma.io) (Large preview) Also, Next.js announced ahead-of-time and incremental static generation, which allows us to add new static pages at runtime and update existing pages after they've been already built, by re-rendering them in the background as traffic comes in.
Need an even more lightweight approach? In his talk on Eleventy, Alpine and Tailwind: towards a lightweight Jamstack, Nicola Goutay explains the differences between CSR, SSR and everything-in-between, and shows how to use a more lightweight approach — along with a GitHub repo that shows the approach in practice.
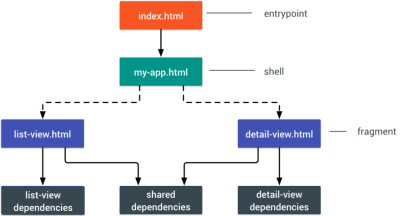
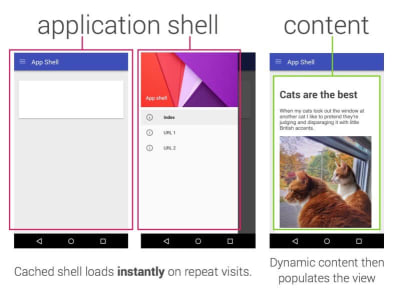
- Consider using PRPL pattern and app shell architecture.
Different frameworks will have different effects on performance and will require different strategies of optimization, so you have to clearly understand all of the nuts and bolts of the framework you’ll be relying on. When building a web app, look into the PRPL pattern and application shell architecture. The idea is quite straightforward: Push the minimal code needed to get interactive for the initial route to render quickly, then use service worker for caching and pre-caching resources and then lazy-load routes that you need, asynchronously.
- Have you optimized the performance of your APIs?
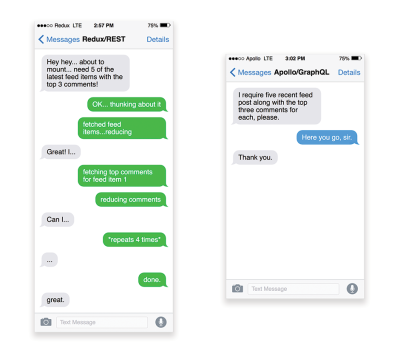
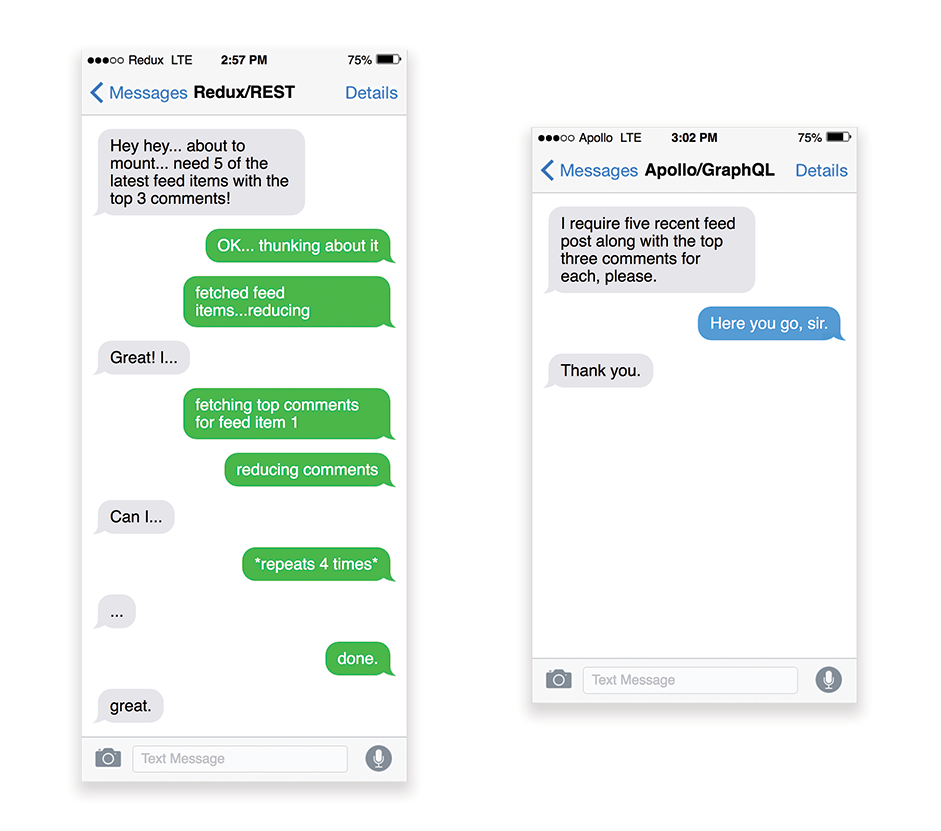
APIs are communication channels for an application to expose data to internal and third-party applications via endpoints. When designing and building an API, we need a reasonable protocol to enable the communication between the server and third-party requests. Representational State Transfer (REST) is a well-established, logical choice: it defines a set of constraints that developers follow to make content accessible in a performant, reliable and scalable fashion. Web services that conform to the REST constraints, are called RESTful web services.As with good ol' HTTP requests, when data is retrieved from an API, any delay in server response will propagate to the end user, hence delaying rendering. When a resource wants to retrieve some data from an API, it will need to request the data from the corresponding endpoint. A component that renders data from several resources, such as an article with comments and author photos in each comment, may need several roundtrips to the server to fetch all the data before it can be rendered. Furthermore, the amount of data returned through REST is often more than what is needed to render that component.
If many resources require data from an API, the API might become a performance bottleneck. GraphQL provides a performant solution to these issues. Per se, GraphQL is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. Unlike REST, GraphQL can retrieve all data in a single request, and the response will be exactly what is required, without over or under-fetching data as it typically happens with REST.
In addition, because GraphQL is using schema (metadata that tells how the data is structured), it can already organize data into the preferred structure, so, for example, with GraphQL, we could remove JavaScript code used for dealing with state management, producing a cleaner application code that runs faster on the client.
If you want to get started with GraphQL or encounter performance issues, these articles might be quite helpful:
- A GraphQL Primer: Why We Need A New Kind Of API by Eric Baer,
- A GraphQL Primer: The Evolution Of API Design by Eric Baer,
- Designing a GraphQL server for optimal performance by Leonardo Losoviz,
- GraphQL performance explained by Wojciech Trocki.
- Will you be using AMP or Instant Articles?
Depending on the priorities and strategy of your organization, you might want to consider using Google’s AMP or Facebook’s Instant Articles or Apple’s Apple News. You can achieve good performance without them, but AMP does provide a solid performance framework with a free content delivery network (CDN), while Instant Articles will boost your visibility and performance on Facebook.The seemingly obvious benefit of these technologies for users is guaranteed performance, so at times they might even prefer AMP-/Apple News/Instant Pages-links over "regular" and potentially bloated pages. For content-heavy websites that are dealing with a lot of third-party content, these options could potentially help speed up render times dramatically.
Unless they don't. According to Tim Kadlec, for example, "AMP documents tend to be faster than their counterparts, but they don’t necessarily mean a page is performant. AMP is not what makes the biggest difference from a performance perspective."
A benefit for the website owner is obvious: discoverability of these formats on their respective platforms and increased visibility in search engines.
Well, at least that's how it used to be. As AMP is no longer a requirement for Top Stories, publishers might be moving away from AMP to a traditional stack instead (thanks, Barry!).
Still, you could build progressive web AMPs, too, by reusing AMPs as a data source for your PWA. Downside? Obviously, a presence in a walled garden places developers in a position to produce and maintain a separate version of their content, and in case of Instant Articles and Apple News without actual URLs (thanks Addy, Jeremy!).
- Choose your CDN wisely.
As mentioned above, depending on how much dynamic data you have, you might be able to "outsource" some part of the content to a static site generator, pushing it to a CDN and serving a static version from it, thus avoiding requests to the server. In fact, some of those generators are actually website compilers with many automated optimizations provided out of the box. As compilers add optimizations over time, the compiled output gets smaller and faster over time.Notice that CDNs can serve (and offload) dynamic content as well. So, restricting your CDN to static assets is not necessary. Double-check whether your CDN performs compression and conversion (e.g. image optimization and resizing at the edge), whether they provide support for servers workers, A/B testing, as well as edge-side includes, which assemble static and dynamic parts of pages at the CDN’s edge (i.e. the server closest to the user), and other tasks. Also, check if your CDN supports HTTP over QUIC (HTTP/3).
Katie Hempenius has written a fantastic guide to CDNs that provides insights on how to choose a good CDN, how to finetune it and all the little things to keep in mind when evaluating one. In general, it’s a good idea to cache content as aggressively as possible and enable CDN performance features like Brotli, TLS 1.3, HTTP/2, and HTTP/3.
Note: based on research by Patrick Meenan and Andy Davies, HTTP/2 prioritization is effectively broken on many CDNs, so be careful when choosing a CDN. Patrick has more details in his talk on HTTP/2 Prioritization (thanks, Barry!).
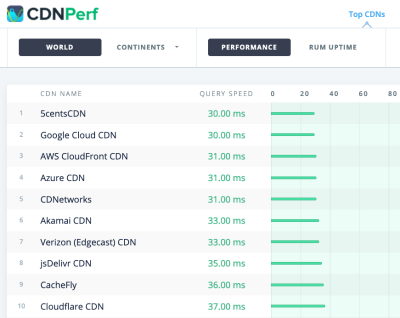
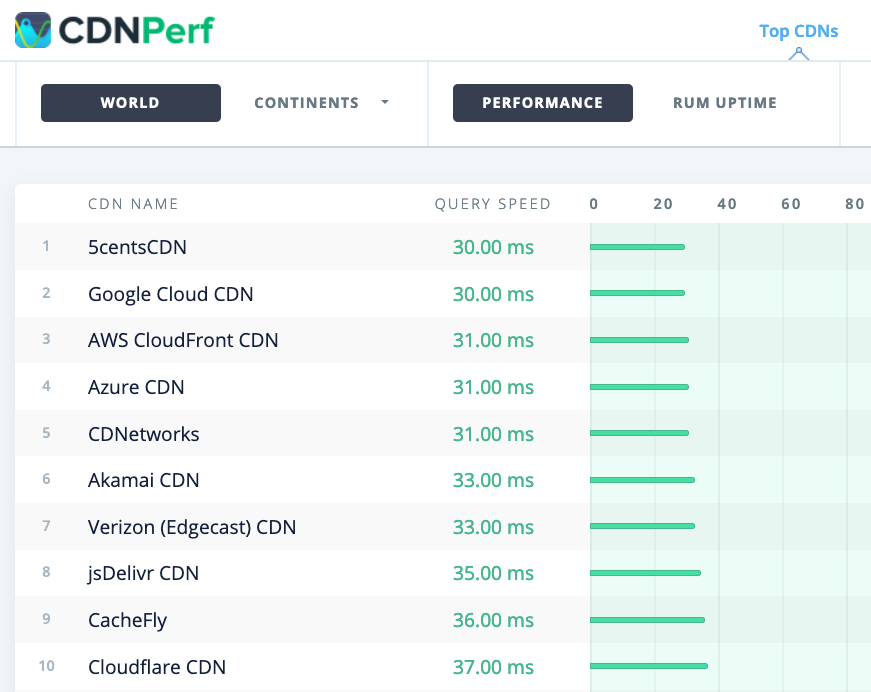
CDNPerf measures query speed for CDNs by gathering and analyzing 300 million tests every day. (Large preview) When choosing a CDN, you can use these comparison sites with a detailed overview of their features:
- CDN Comparison, a CDN comparison matrix for Cloudfront, Aazure, KeyCDN, Fastly, Verizon, Stackpach, Akamai and many others.
- CDN Perf measures query speed for CDNs by gathering and analyzing 300 million tests every day, with all results based on RUM data from users all over the world. Also check DNS Performance comparison and Cloud Peformance Comparison.
- CDN Planet Guides provides an overview of CDNs for specific topics, such as Serve Stale, Purge, Origin Shield, Prefetch and Compression.
- Web Almanac: CDN Adoption and Usage provides insights on top CDN providers, their RTT and TLS management, TLS negotiation time, HTTP/2 adoption and others. (Unfortunately, the data is only from 2019).
{kind=link}
Table Of Contents
- Getting Ready: Planning And Metrics
- Setting Realistic Goals
- Defining The Environment
- Assets Optimizations
- Build Optimizations
- Delivery Optimizations
- Networking, HTTP/2, HTTP/3
- Testing And Monitoring
- Quick Wins
- Everything on one page
- Download The Checklist (PDF, Apple Pages, MS Word)
- Subscribe to our email newsletter to not miss the next guides.
Further Reading
- How To Boost Media Performance On A Budget
- Optimizing Video For Size And Quality
- How To Implement Authentication In Next.js With Auth0
- An In-Depth Guide To Measuring Core Web Vitals